Présentations des étudiant-es

Licence CC-Zero
INTRODUCTION
Nous avons toutes et tous déjà entendu parler de l’intelligence artificielle et de ses algorithmes, sans forcément savoir quelles sont leurs applications, ni même vraiment comprendre leur fonction. Une chose est sûre : nous y sommes confrontés chaque jour, si ce n’est chaque heure, ou du moins bien plus souvent que nous pouvons le penser. Il est vrai que les algorithmes peuvent faciliter bien des opérations dans de très nombreux domaines, mais il s’agit d’outils imparfaits qui peuvent parfois mener à des discriminations. Nous avons donc décidé de nous intéresser à ces limites : dans quelles situations l’algorithme est-il vecteur de biais? Quelles sont les limites de son utilisation? Quel impact peut-il avoir sur nous, les êtres humains, dans notre vie de tous les jours? Et surtout, que pouvons-nous faire pour limiter les discriminations?
À travers un ensemble de vidéos sur les biais algorithmiques, nous suivrons Inaja, qui sera confrontée à divers biais issus de cet outil tout au long de sa journée. Ainsi nous tenterons de répondre à ces questions. Bon visionnage!
Inaja face aux biais des algorithmes
Plongée dans les dessous des algorithmes (machine learning)
Besoin de plus d'infos sur le machine learning? Regardez la vidéo de pixees Scienceparticipative pour en savoir plus!
Les biais algorithmiques rencontrés par Inaja
Agir contre les biais algorithmiques
PRÉSENTATION DE L'ÉQUIPE
Etudiant-es du cours transversal sur le numérique
Jésus BERMUDEZ
Catalina HERRERA DEVIA
Pattara LASING
Aïssata LINDER
Noémie PRALAT
Bertille TRIBOULET
Référente / Faculté des Lettres/ CUI
Paola MERLO
Assistant-es du cours transversal sur le numérique
Margherita PALLOTTINO
Fabrice CAMUS
MOTS-CLÉS
Biais algorithmique (Algorithmic Bias)
Phénomène qui altère le résultat d’un algorithme en le rendant partial, non-neutre, voire préjudiciable.
Dommage (Harm)
Préjudices que les algorithmes et leur utilisation causent à une société, ou une partie de celle-ci.
Prise de conscience (Awareness)
Les biais implicites concernent les attitudes, réactions, stéréotypes et catégories inconscientes qui affectent le comportement et la compréhension. Il s'agit donc de sensibiliser les individus quant à l'existence de ces biais et promouvoir une pratique éthique et responsable.
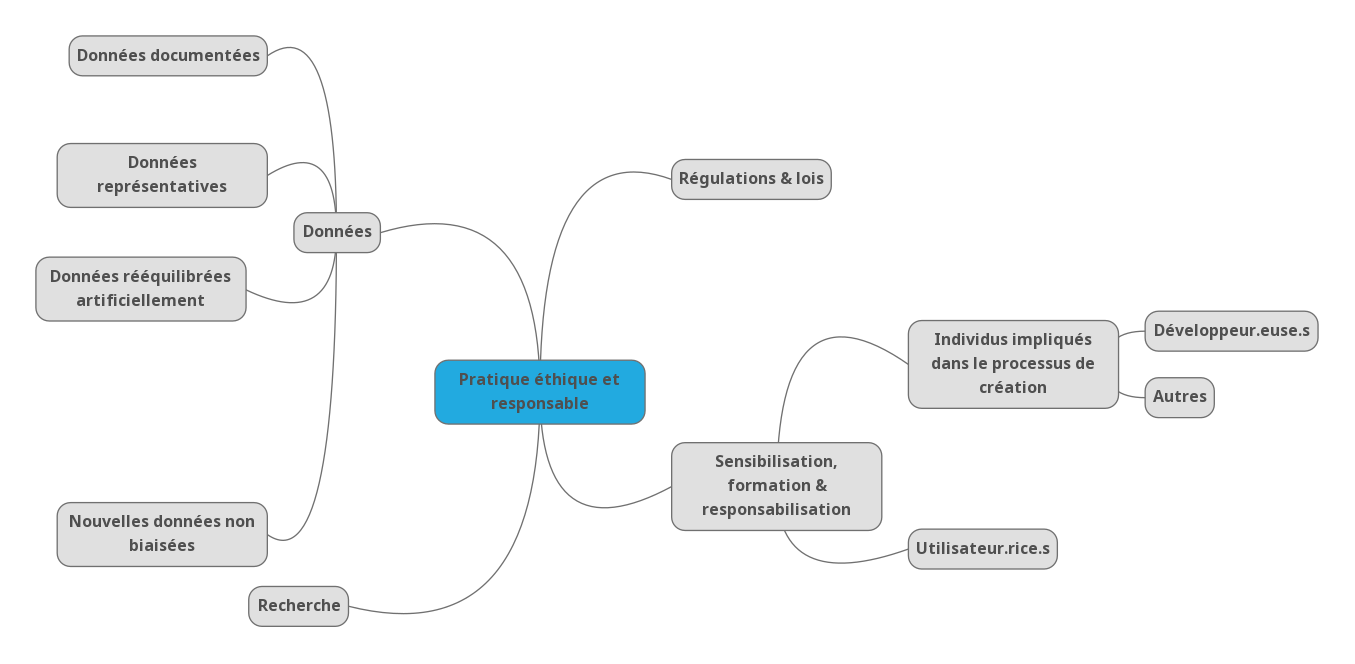
STRATÉGIES POUR UNE PRATIQUE ÉTHIQUE ET RESPONSABLE
cliquez sur l'image pour l'agrandir
LES BIAIS ALGORITHMIQUES EN QUELQUES MOTS
Qu'est-ce qu'un algorithme ?
Un algorithme désigne une séquence d’opérations qui doivent être exécutées dans un ordre précis pour résoudre un problème. L’algorithme est une notion qui nous vient des mathématiques, mais elle a ensuite été appliquée à de très nombreux autres domaines.
Dans le machine learning (ou « apprentissage automatique »), les algorithmes sont essentiels car ils permettent à la machine de traiter les données qui lui sont fournies pour pouvoir apprendre et être capable par la suite de faire des prédictions ou des analyses. On distingue deux grands types d’algorithmes d’apprentissage : les algorithmes supervisés et non-supervisés.
Dans le cas de l’apprentissage supervisé, les données fournies à l’algorithme pour son apprentissage sont étiquetées par des humains au préalable : on dit à la machine à quoi les données correspondent pour qu’elle puisse reconnaître une donnée similaire sans étiquette par la suite.
Pour l’apprentissage non-supervisé, au contraire, on ne donne pas d’information supplémentaire à l’algorithme : la machine doit analyser seule l’ensemble des données pour observer de potentielles structures ou tendances.
Qu'est-ce qu'un biais algorithmique ?
À l’instar du biais cognitif, c’est-à-dire un mécanisme de pensée qui vient fausser le jugement d’un individu, le biais algorithmique est un phénomène qui altère le résultat d’un algorithme en le rendant partial, non-neutre, voire préjudiciable.
Quelles conséquences les biais algorithmiques peuvent-ils avoir sur nous ?
Les biais algorithmiques peuvent avoir des conséquences plus ou moins importantes sur nous. En effet, des résultats biaisés peuvent être relativement inoffensifs, comme lorsqu’un correcteur automatique de téléphone modifie un mot qu’il n’aurait pas dû ou qu’un moteur de recherche sur internet affiche des photos de chiens alors que l’on a cherché « chat ». Mais à mesure que les algorithmes sont déployés dans toujours plus de domaines, au sein de la police, de la justice ou dans la médecine par exemple, les biais peuvent avoir des conséquences plus graves. Si un système de reconnaissance faciale fonctionne moins bien sur un groupe d’individus que sur un autre, les personnes sous-représentées peuvent alors avoir des difficultés à déverrouiller leur téléphone ou à être correctement identifiées par le système de sécurité d’un aéroport. Les biais algorithmiques peuvent aussi favoriser la discrimination avec des résultats de prévision de récidive inégaux ou encore des calculs de limite de crédits partiaux. Il ne s’agit là que de quelques exemples d’une liste infinie. L’intelligence artificielle et les algorithmes sont certes devenus des outils précieux, voire indispensables, mais il faut tout de même manier leurs résultats avec prudence.
Comment les biais se retrouvent-ils dans les algorithmes ?
Bien que les algorithmes d’entraînement reposent sur des séquences mathématiques, ils restent le produit des humains, tout comme les données qui leur sont fournies. Tout au long du processus de développement et de diffusion d’un algorithme, nous pouvons donc lui transmettre nos propres préjugés qu’il va ensuite reproduire, voire amplifier, et potentiellement devenir la source de discriminations.
Il peut s’agir des développeur.euse.s, qui, sans le vouloir, n’utilisent pas les données appropriées pour entraîner les algorithmes et sur/sous-représentent alors un ou des groupes d’individus. Mais les discriminations liées aux algorithmes peuvent également être intentionnelles, comme dans le cas de l’algorithme de Tinder qui associe les personnes les unes aux autres en fonction d’une note de désirabilité basée sur des critères jugés sexistes et discriminatoires.
D’autres acteurs peuvent avoir une influence sur ce phénomène. C’est le cas notamment des personnes qui annotent les données des algorithmes supervisés : en associant des informations précises aux données, elles donnent leur propre vision du monde et peuvent transmettre leurs préjugés.
Par ailleurs, certains biais existent déjà dans les données avant même qu’elles ne soient utilisées d’une quelconque façon : ce sont les biais sociétaux. Dans ce cas, ils sont inhérents aux données et reflètent des inégalités et/ou discriminations propres à la société dans laquelle elles ont été collectées.
Comment peut-on lutter contre les biais algorithmiques ?
La communauté scientifique se penche sur la question depuis quelques années, mais il n’existe pas de solution miracle qui empêcherait systématiquement tous les biais d’être reproduits et amplifiés par les algorithmes. On trouve en revanche plusieurs idées de pratiques qui peuvent être combinées pour réduire les biais et surtout réduire leur impact sur la société.
Une première piste serait d’améliorer la qualité des données d’entraînement. L’idée est d’obtenir des ensembles de données le plus représentatifs possible, adaptés aux besoins précis de chaque algorithme et bien annotés le cas échéant. Pour cela, il faut donc viser la qualité plutôt que la quantité, bien définir les besoins de chaque projet et avoir des ensembles de données bien documentés sur leur contenu et la façon dont il a été collecté. Cela permet en effet d’identifier plus facilement les biais s’il y en a et de donner des informations précises aux personnes qui voudraient réutiliser ces données par la suite.
La sensibilisation de tous quant à ces biais potentiels et les risques de discrimination qu’ils représentent constituent la base d’une autre branche de solutions envisagées. Cela concerne avant tout les développeur.euse.s et autres personnes impliquées dans le processus de création des algorithmes qui pourraient être plus sensibilisés au cours de leur formation. Mais cela se rapporte également aux utilisateur.rice.s de ces algorithmes, et plus particulièrement les professionnels, car ils peuvent prendre des décisions discriminatoires sans le savoir. Il est donc important qu’une prise de conscience collective s’opère, pour réduire les biais dans les algorithmes et pour prendre du recul vis-à-vis de leurs résultats. Cela nous permettrait d’éviter les biais d’automatisation, c’est-à-dire de reproduire des biais algorithmiques en considérant que l’intelligence artificielle est plus objective et fiable que l’humain.
Pour aller vers une pratique plus responsable et éthique de l’intelligence artificielle et des algorithmes, les autorités cherchent depuis quelques années à encadrer et réguler la création et l’utilisation des algorithmes. Cela permettrait également de responsabiliser les différents acteurs qui y sont liés. Il s’agit cependant d’un processus très lent et difficile à mettre en place, notamment en raison des nombreuses zones de flou qui existent encore sur le plan technique. Il s’agit donc principalement de recommandations et de lignes directrices faites par différents organismes, tels que le Défenseur des droits et la CNIL, l’Union Européenne ou l’OCDE. Toutefois, l’Union Européenne a rendu public en avril 2021 un projet de loi qui permettra d’aller plus loin dans cette régulation et de manière plus uniforme. Malgré l’avancée inédite que représente ce projet, son plus grand défi concerne justement les données puisqu’il vise à ce que celles-ci ne comportent pas de biais intentionnels ou non intentionnels susceptibles de faciliter la discrimination. Or la partialité des données reste encore difficile à prouver, difficile à traiter et profondément liée aux cultures centrales des organismes de collecte de données. La question place donc de plus en plus les organismes de recherche privés et publics dans un chassé-croisé entre la nécessité de représenter avec précision des groupes distincts (pratiquement l'objectif fondateur des mathématiques computationnelles et de l'analyse statistique empirique) et le potentiel de promulgation, entre autres, du profilage racial et de la diabolisation culturelle.
En tant qu’universitaire, que puis-je faire?
En tant qu’universitaire, il est évidemment possible de prendre part aux recherches et de faire avancer les connaissances scientifiques sur le sujet.
Il est également possible de lutter contre les biais algorithmiques sans être dans la recherche sur l’intelligence artificielle : on peut, par exemple, décider de participer à la création de données non biaisées en choisissant de publier des papiers en français en conservant des helvétismes ou en optant pour une écriture inclusive ou un féminin générique.
MENTION LÉGALE
Cours transversal : comprendre le numérique, Margherita Pallottino, Fabrice Camus, Jésus Bermudez, Catalina Herrera Devia, Pattara Lasing, Aïssata Linder, Noémie Pralat, Bertille Triboulet, License CC BY