Introduction to generative AI
Talking about Artificial Intelligence (AI) induces the bias of picturing intelligence according to our human perception of what it can be. Its contours are ill-defined, but we generally agree to have a common understanding that relates to our ability to perform certain tasks with a degree of skill. The computer analogy, by adding the qualifier "artificial," does not help in understanding what AI is or what it can do, as it does not share the same skill mapping.
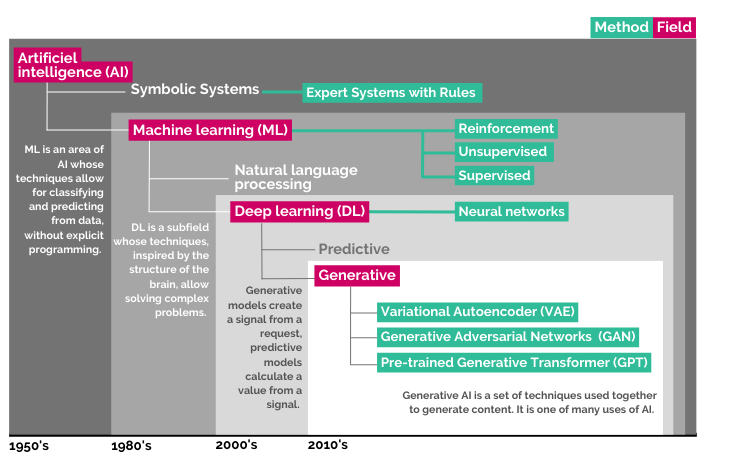
The term generative AI refers to a set of techniques (i.e., algorithms) stemming from the field of artificial intelligence. What is meant by "generative" is the tool's ability to automatically create content from large volumes of existing data on which it is trained. AI does not simply copy and paste what it has analyzed: it imitates, enhances, and creates entirely new content based on a statistical recombination of patterns and structures it identified during its training. This content can include texts, images, music, or computer code.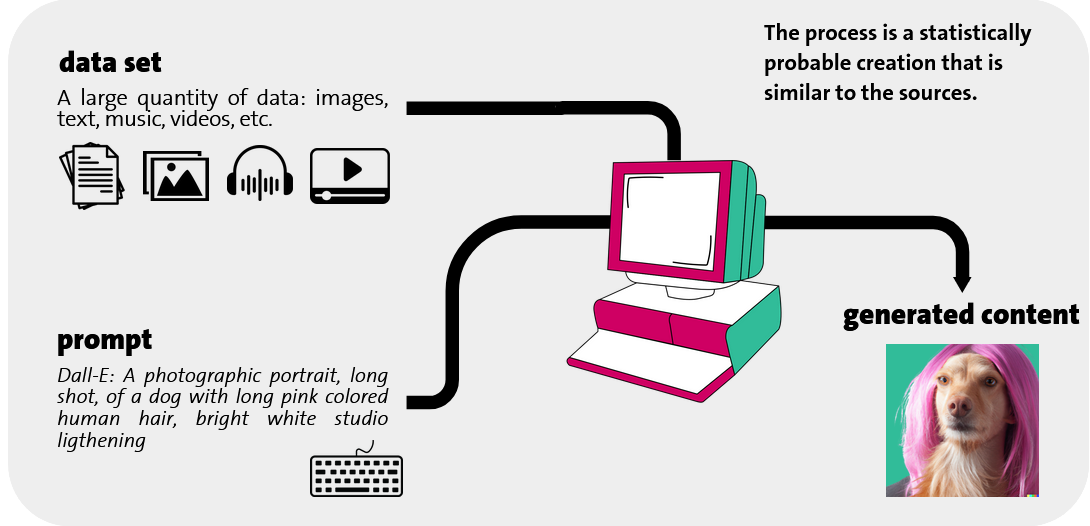
AI learns the rules by analyzing thousands of texts, images or pieces of music (data set). It studies how they are arranged and detects recurring patterns, which it then uses to generate new content based on a query (prompt).
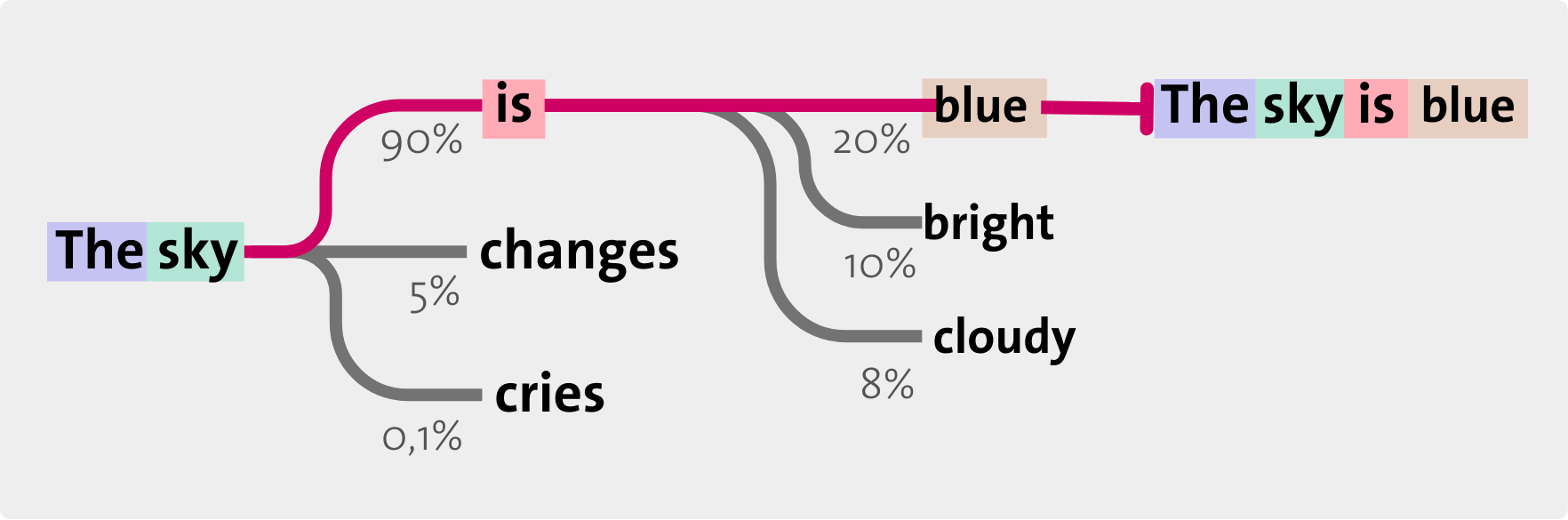
The content generated by AI is statistically recomposed from everything it has learned. It makes sense because it adheres to the grammatical, visual, or musical rules extracted from the training data sets. These rules are memorized in the form of a Large Language Model (LLM, see p. 9). This allows, among other things, the synthesis of information or the proposal of original content.
It is large because it has an enormous number of parameters (on the order of billions), which are pieces of information. It is a model because it is a neural network trained on a large amount of texts to perform non-specific tasks. It is linguistic because it reproduces the syntax and semantics of human natural language by predicting the likely continuation for a certain input. This also allows it to have a "general knowledge" based on the training texts.