Introduction à l'IA générative
Parler d’intelligence artificielle (IA) induit le biais de se représenter l’intelligence selon notre perception humaine de ce qu’elle peut être. Ses contours sont mal définis, mais nous nous accordons généralement pour en avoir une idée commune qui se rapporte à notre capacité à effectuer certaines tâches avec un certain degré de compétence. L’analogie informatique par l’ajout du qualificatif «artificielle» ne permet pas de comprendre ce qu’est une IA, ni ce qu’elle peut faire, car elle ne partage pas la même cartographie de compétences.
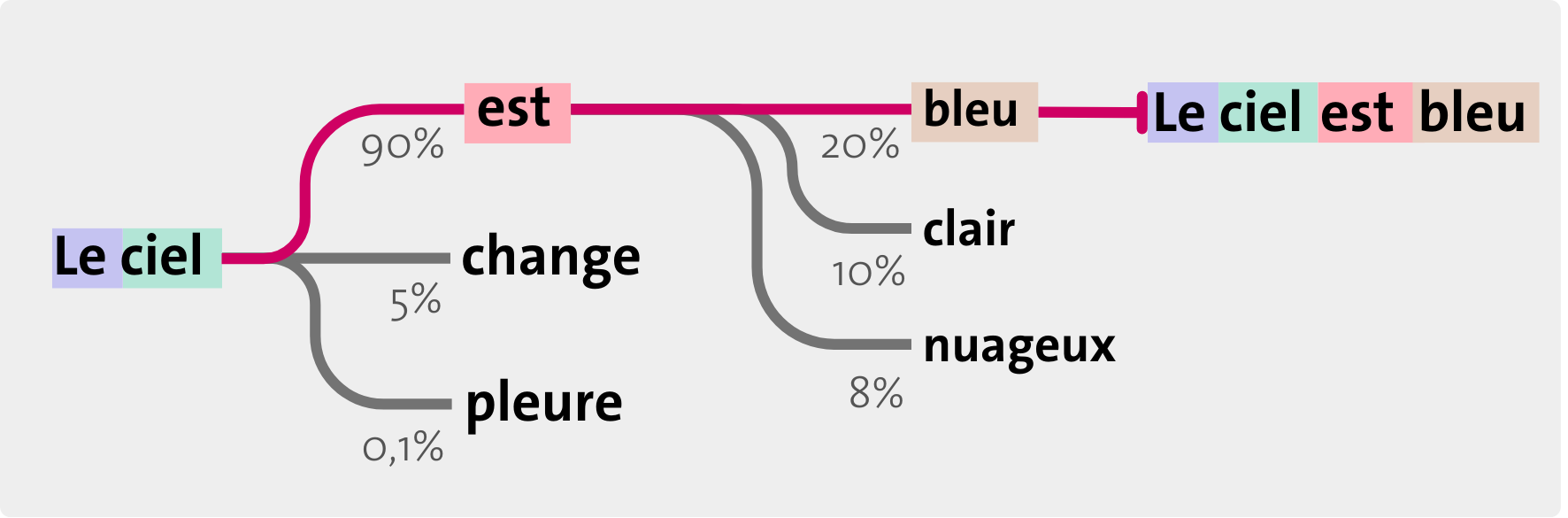
Ce que l’on entend par le terme de «générative» est la capacité de l’IA à créer de l’information de manière automatique à partir de grands volumes de données existantes sur lesquelles elle est entraînée. L’IA ne fait pas de simple copier-coller de ce qu’elle a analysé: elle imite, améliore et crée un résultat entièrement nouveau, basé sur une recomposition statistique des motifs et structures qu’elle a identifiés pendant son apprentissage. Ces résultats, que l’on appelle contenus, peuvent être des textes, des images, de la musique ou du code informatique.
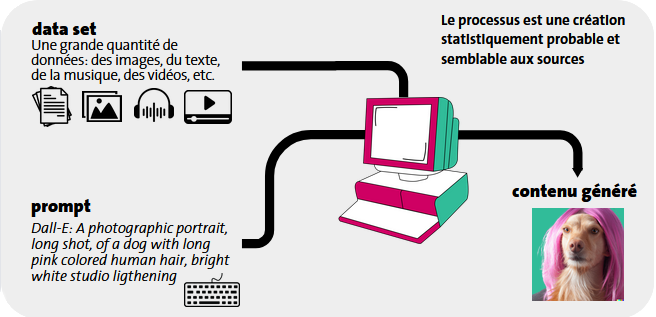
L’IA apprend les règles en analysant des milliers de textes, images ou morceaux de musique (data set). Elle étudie la manière dont ils sont arrangés et détecte des motifs récurrents qu’elle utilise ensuite pour générer de nouveaux contenus en fonction d’une requête (prompt).
Les contenus générés par l’IA sont des recompositions statistiques de tout ce qui a été appris. Ils ont du sens parce qu’ils respectent les règles grammaticales, visuelles ou musicales extraites des data sets d’entraînement. Ces règles sont mémorisées sous forme d’un Large Language Model (LLM, voir ci-dessous). Cela permet, entre autres, de synthétiser des informations ou de proposer des contenus originaux.
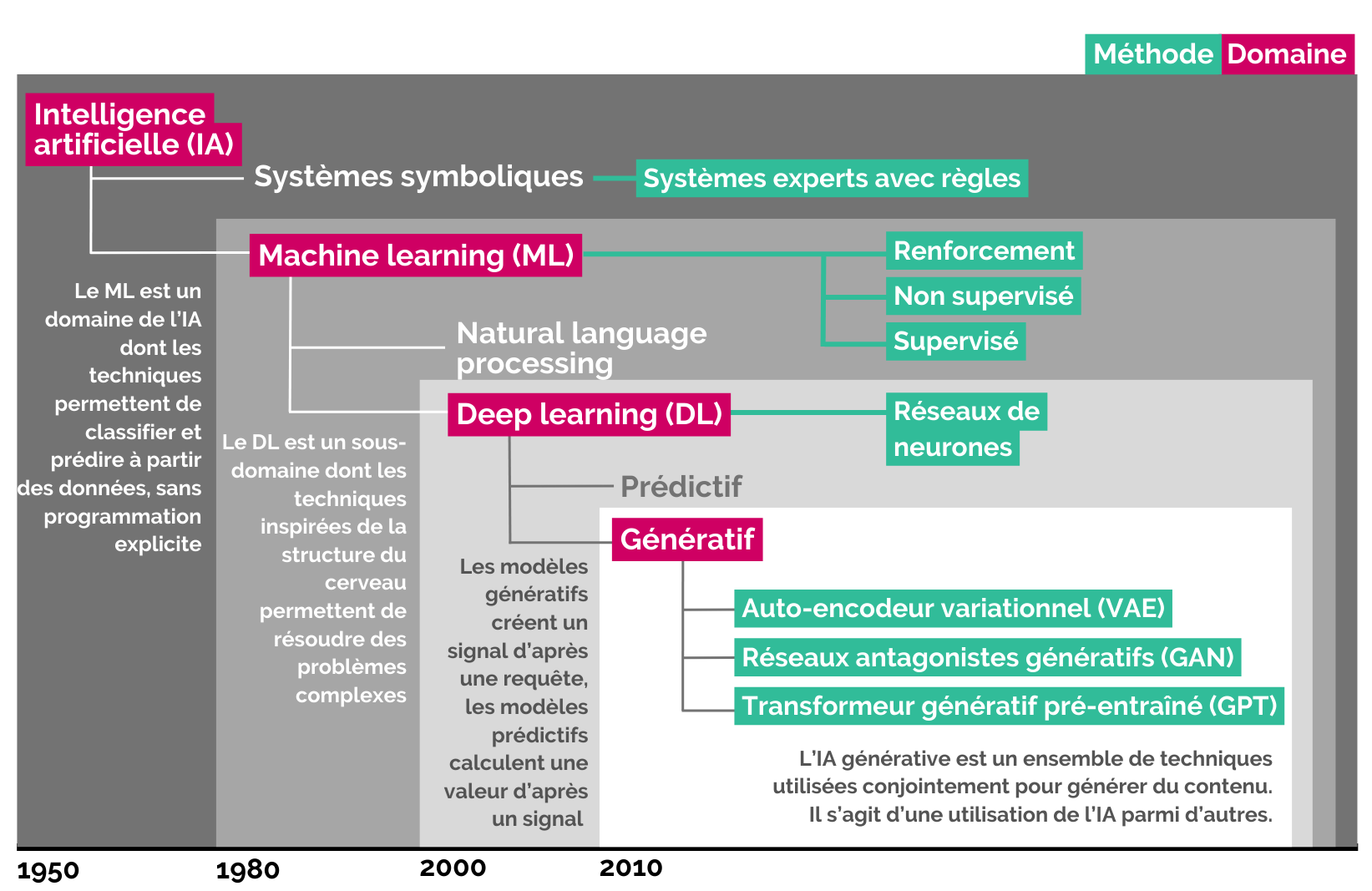
Un LLM est large, car il possède énormément de paramètres (de l’ordre de plusieurs milliards), qui sont autant de pièces d’information. C’est un modèle, car il s’agit d’un réseau de neurones entraîné sur une grande quantité de textes pour produire des tâches non spécifiques. Il est linguistique, car il reproduit la syntaxe et la sémantique du langage naturel humain en prédisant la suite probable pour une certaine entrée. Cela lui permet également d’avoir une «connaissance» générale sur la base des textes d’entraînement.