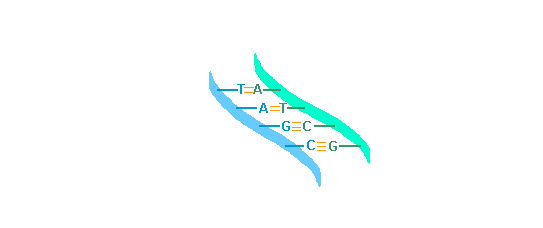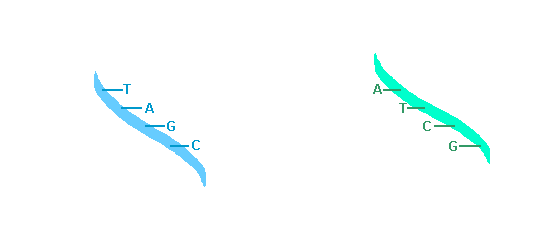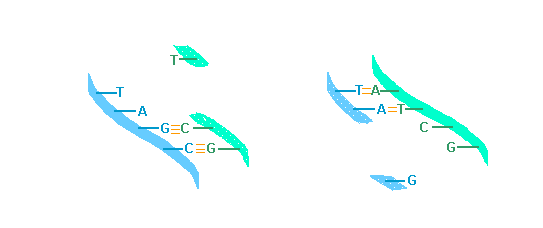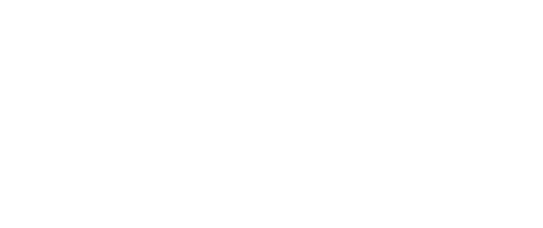The spectacular recent progress in genetics is the result of accumulated knowledge in several branches of biology and biochemistry that are the fruit of long years of basic research.
| I. FROM THE ORGANISM TO THE GENE |
| II. GENES |
| III. PROTEINS |
| IV. GENETIC INFORMATION |
| V. MUTATIONS |
I. FROM THE ORGANISM TO THE GENE
|
Related Current Themes |
Related Techniques |
What is the relationship between organism and gene?
The cell is the organizing principle that links organisms and genes. All living organisms are composed of cells.
For a complex organism such as a human being, each cell of an adult is specialized for a particular function related
to the organ in which it occurs, as well as its role in the organ (heart cells, neurons, stomach lining, skin cells,
liver cells, etc.). Nevertheless, virtually all cells share many common properties, including a large nucleus several
microns in diameter (that generally occupies about 10% of the cell volume), containing the chromosomes upon which
are located the genes.
The specialized role of each particular type of cell, as well as various "housekeeping" functions common
to all cells, are determined principally by the genes in the nucleus of the cell. In humans, the genes are organized
in 22 pairs of chromosomes (one member of each pair obtained from each parent), plus the chromosomes X and X (in
a female) or X and Y (in a male). In both cases, one X chromosome is received from the mother, and the father contributes
either an X or a Y chromosome (the sex is determined by the sperm that fertilizes the egg of the future individual,
either an X-carrying sperm or a Y-carrying sperm).
How do cells become specialized during
development?
As the fertilized egg undergoes successive cell divisions, producing greater and greater numbers of cells, these
cells become specialized because certain genes are activated and other genes are quiescent. The fertilized egg
is totipotent -- it can give rise to all cells of the body, as well as the cells of the placenta. Other cells isolated
from early embryos, the embryonic stem (ES) cells, are pleuripotent, that is they have the capacity to differentiate
into any of the different forms of specialized adult cells. Such cells can be isolated from embryos, grown in the
laboratory, and in the presence of a specific growth factors can be stimulated to differentiate into a specialized
cell type (muscle, nerve, etc.).
In conclusion, the relationship between gene and organism is determined by the specialization of cells during development.
As the organism advances to its final stages prior to birth, most cells have become highly differentiated. However,
small numbers of stem cells can still be found in many tissues; they are not as versatile as the pleuripotent ES
cells, but these multipotent cells can be triggered by specific growth factors to change into other cell types
and are of great interest to medical researchers. In general, the specialization of the cells results from the
fact that each gene that is activated leads to the synthesis of a specific protein. Therefore, each cell contains
thousands of different proteins. Some are the "housekeeping" proteins that are found in nearly all cells
and, for example, catalyze the basic reactions needed to metabolize sugars and fats that keep the cells alive,
as well as to produce the various chemical building blocks that the cell requires to renew its structures. Other
specific proteins perform specialized functions, such as insulin synthesized only in certain cells of the pancreas,
hemoglobin that is present only in the red blood cells, and various receptors of neurotransmitters that occur only
in neurons.
Do all organisms operate along the
same principles?
The union of egg and sperm to initiate development occurs in complex, multi-cellular animals. In order to provide
a more complete explanation of the relation between gene and organism, two additional aspects must be considered:
1. Plants and animals are composed of eucaryotic cells. The term "eucaryotic" means "true nucleus"
and these cells contain multiple chromosomes organized in a distinct nucleus. Other simpler unicellular organisms,
such as bacteria, are much smaller and contain a single chromosome that is not isolated within a nucleus. Such
cells without a distinct nucleus are called procaryotic cells. Unicellular organisms constituted by a eucaryotic
cell exist as well, as represented for example by yeast. Bacteria can be responsible for diseases, such as tuberculosis,
but can also play a positive role, for example in the production of yogurt. Moreover, the intestinal bacteria of
human beings are a necessary feature of the digestive system. Indeed, there are more procaryotic bacterial cells
in the gut than eucaryotic cells in the body!
2. Eucaryotic cells contain specialized structures (organelles), in addition to the nucleus, that perform specialized
functions. For example, eucaryotic cells contain mitochondria that carry out many of the reactions essential for
energy production. Mitochondria are roughly the size of bacteria and indeed may represent descendents of bacteria
that were "captured" at an early stage in the evolution of eucaryotic cells. Mitochondria also contain
a simple chromosome with genes that code for a small number of proteins necessary for mitochondrial function; many
other mitochondrial proteins are synthesized under control of genes in the nucleus and then imported into the mitochondria.
All mitochondria are derived from the egg and thus are entirely of maternal origin. During cell division, mitochondria
also divide, so their numbers per cell remain relatively constant. In plant cells, other specialized organelles
called chloroplasts (which also contain a small chromosome with genes that synthesize specific proteins) carry
out reactions of photosynthesis.
What is a chromosome?
The chromosome is a long complex composed of one molecule of double-stranded DNA surrounded by thousands of proteins
(the histones). It can be visualized in a dense, compacted form when cells divide (mitosis). The 46 chromosomes
of humans can be aligned according to size to establish the gallery of forms that is known as the karyotype. Certain
genetic diseases have been correlated with changes in the number or appearance of chromosomes, as visualized under
a microscope, as in the case of trisomy 21, which can be detected prenatally by examining the karyotype of cells
removed by amniocentesis. For a genetic disease that leads to mental retardation, the fragile-X syndrome, the X
chromosome appears broken near one end when a karyotype is established.
A mid-sized chromosome (number 9) is about 2.5 microns long when compacted and contains a molecule of DNA with
about 150 million base pairs (which corresponds to a length of about 50 mm or 50,000 microns). Hence, in the dense
chromosome, the DNA molecule is compacted about 20,000 times by being coiled into smaller and smaller units: first,
beads of DNA wrapped around a histone core (to give the "nucleosome"); then, tightly packed ribbons of
nucleosomes; and finally, loops of these nucleosome ribbons aligned in the dense pattern that produces the intact
chromosome. The stages of compacting are illustrated in the figure below, with the histone core of the nucleosomes
represented by the green cylinders.
CHROMATIN

What is heredity?
In the early part of the 20th century, biologists established the connection between genetic traits and chromosomes,
in large measure from studies on the fruit fly, Drosophila. Individual traits such as eye color were found to "map"
along chromosomes in a linear relationship. These studies lead to the basic concept that there are definite structures
encoded in the genes on chromosomes (the genotype) that are responsible for various observable properties of the
organism (the phenotype). Nevertheless, the phenotype may also be influenced by factors in the environment. For
example, if obesity is considered as a phenotype, it may occur in individuals who have inherited a genetic defect,
or it may be provoked in genetically "normal" individuals by a cultural environment that favors a sedentary
life style and inappropriate nutrition.
The underlying chemical basis of how the genotype can alter the phenotype remained inaccessible until the second
half of the 20th century. Chromosomes were known to contain the nucleic acid DNA, but a key insight was missing
to link such molecules to genetics, because initially their complexity, based on only four classes of building
blocks, was underestimated. It was necessary to await the results of experiments using bacteria and their viruses
that furnished direct evidence concerning the predominant role of DNA. Even so, the participation of DNA in the
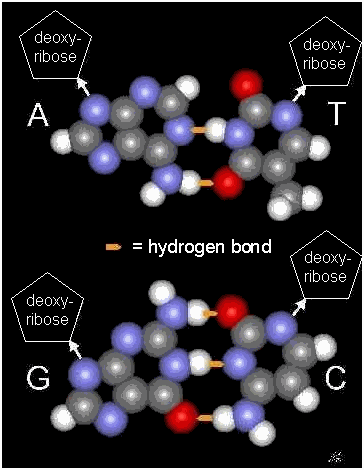
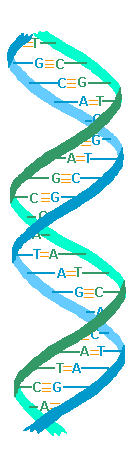
genetic mechanism remained obscure until Watson and Crick published their model for DNA in 1952, the famous double
helix.