
Quand le four n'est pas assez grand...
Béatrice Joyeux-Prunel & Nicola Carboni
Pour étudier la circulation des images dans les périodiques illustrés, nous partons de millions de pages numérisées.
Toutes sont déjà servies, ou passées par nous-mêmes, sous un format des plus souples, format commun à la plupart des grandes bibliothèques numériques du monde : le format IIIF (International Image Interoperability Framework)[1].
Les imprimés illustrés du corpus sont chargés à partir de leurs identifiants dans une plateforme, visualcontagions.unige.ch/explore.
Là, un algorithme extrait automatiquement des pages toutes leurs illustrations.
Il nous faudra encore du temps pour analyser toutes les pages de nos documents, et pour en isoler toutes les images. A l’heure du montage de cette exposition (avril 2022), 153914 items ont été « explorés », soit 24 % du corpus actuel, items répartis sur 40 pays et 301 villes. La machine en a extrait 3'202'227 images. Le corpus complet, lui-même, recouvre actuellement 121 pays sur la période 1890-2021, et nous allons encore l'augmenter dans les mois qui viennent.
La carte qui suit présente ce corpus - laissez-la charger quelques secondes, selon la vitesse de votre connexion. Vous verrez s'afficher progressivement une cartographie quantitative du corpus exploré par l'équipe (c'est à dire, dont les images ont été extraites et regroupées par similarités). La petite interface vous permet de naviguer dans ce corpus selon le temps et l'espace, ou de mettre en route une visualisation temporelle de ces éléments.
--
OU
VEA
Pour ordonner ce déluge, le choix des outils algorithmiques et de leur implémentation est stratégique.
En effet, comparer deux à deux toutes les images d’un stock de 3 millions d’images prendrait un temps dont nous ne disposons pas.
À « l’ancienne » - avec des algorithmes de type SURF et RANSAC conçus pour comparer des images, sans réseaux de neurones - , et sans paralléliser nos calculs, comparer deux à deux nos images prendrait à peu près 300 000 ans[2].
En supposant que nous disposions d’une machine à 32 CPU, l’analyse pourrait aller un peu plus vite – 10 000 ans peut-être. Nous aurions des résultats incroyablement précis sur le contenu de nos images, et sur les images les plus proches les unes des autres. Personne ne serait là pour les voir malheureusement.
D’où l’intérêt, plutôt que de comparer les images deux à deux, de décrire mathématiquement nos images par des vecteurs.
Ceci permet de réaliser un produit scalaire à partir duquel on construit un score de similarité entre images. À partir de ces vecteurs, l’ordinateur construit un graphe dans il repère les sous-ensembles de points les plus proches. Graphiquement, ou plutôt mathématiquement, la machine isolera des groupes d’images similaires. Encore faut-il repérer les algorithmes les plus efficaces et les plus rapides, et pour cela comparer leurs résultats sur des corpus restreints, tirés de nos propres données. Suite à plusieurs évaluations, Visual Contagions a adopté l’algorithme NMSLIB.
En résumé : un projet en vision artificielle améliore sa chaîne de traitement par essais et erreurs.
--
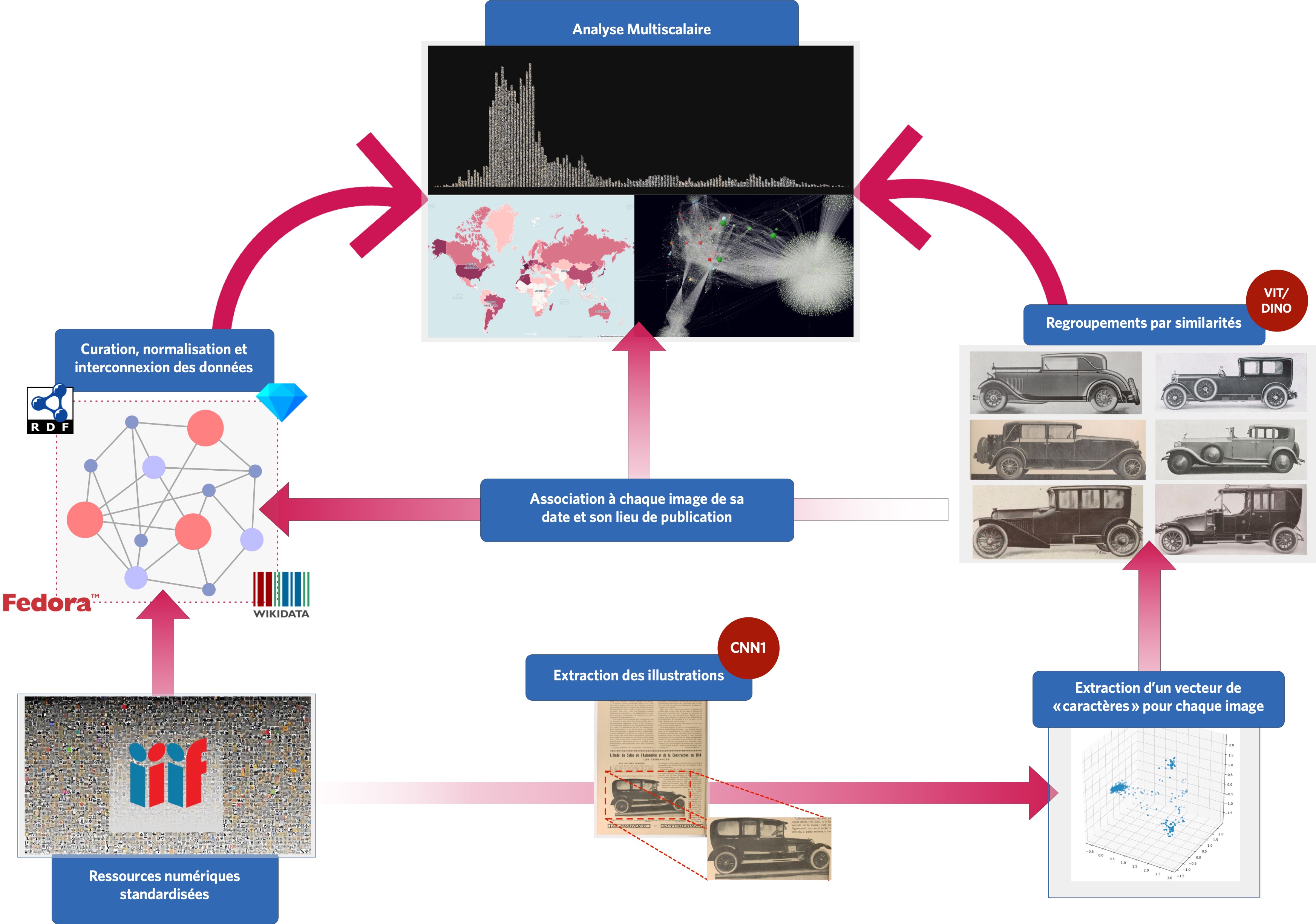
Schéma illustrant le processus d'extraction, de description, d'analyse et de visualisation utilisé par Visual Contagions.
--
Dernier élément de la chaîne, la plateforme Explore permet de récupérer ces groupes d’images similaires, selon un seuil de similarité plus ou moins élevé que nous définissons.
Selon la manière dont nos algorithmes sont réglés, ils peuvent classer les images par groupes plus ou moins gros selon que les images sont plus ou moins proches les unes des autres. Les images sont ensuite réassociées à leurs métadonnées (lieux, dates et source de publication). Il est alors possible de visualiser leurs regroupements, pour repérer les images les plus reproduites, et pour tenter un traitement analytique plus général de l’espace mondial des illustrations du premier vingtième siècle.
Vers l'épisode III : Naviguer dans l'océan des images
Vers ce qui précède :
Les biais de notre corpus
Retour au chapitre :
II. Les promesses de la machine
[1] Selon ce format, chaque document peut être récupéré par une simple adresse internet (une URI), laquelle donne accès à un fichier très léger de texte. Ce fichier qu’on appelle un « manifeste » rassemble, pour un document, la liste noms des fichiers images qui le constituent, l’ordre et l’organisation de ces pages, ainsi que les métadonnées qui le décrivent : titre, date, éditeur, archive, date de mise en ligne... C’est à partir de l’adresse internet de ce manifeste que nous retrouvons aussi bien une image que sa date, son lieu et son titre de publication.
[2] Jinliang Liu, FanLiang Bu, Improved RANSAC features image-matching method based on SURF, 7th International Symposium on Test Automation and Instrumentation (ISTAI 2018), 2019, https://doi.org/10.1049/joe.2018.9198