
When there is not enough room in the oven...
Béatrice Joyeux-Prunel & Nicola Carboni
To study the circulation of images in illustrated periodicals, we start with millions of digitized pages.
All of them are already served, or have been transformed by ourselves, in a very flexible format, a format common to most of the world's major digital libraries:the IIIF format (International Image Interoperability Framework).[1]
The illustrated prints in the corpus are loaded from their identifiers into a platform, visualcontagions.unige.ch/explore.
There, an algorithm automatically extracts all the illustrations from the pages.
It will still take time to analyse all the pages of our documents, and to isolate all the images. By the time this exhibition was initiated (April 2022), 153914 items have been 'explored', i.e. 24% of the current corpus, items spread over 40 countries and 301 cities. The machine has extracted 3,202,227 images. The complete corpus, itself, currently covers 121 countries over the period 1890-2021, and we will increase it further in the coming months.
The following map shows this corpus - let it load for a few seconds, depending on your connection speed. You will progressively see a quantitative mapping of the corpus explored by the team (i.e. from which images have been extracted and grouped by similarities). The small interface allows you to navigate in this corpus according to time and space, or to start a temporal visualization of these elements.
--
OU
VEA
To order this deluge, the choice of algorithmic tools and their implementation is strategic.
Indeed, to compare two by two all the images of a stock of 3 million images would take a time that we do not have.
The "old way" - with algorithms such as SURF and RANSAC designed to compare images, without neural networks - and without parallelizing our calculations, comparing two by two our images would take about 300,000 years.[2]
Assuming we had a 32 CPU machine, the analysis might go a little faster - perhaps 10,000 years. We would have incredibly accurate results on the content of our images, and on the images closest to each other. No one would be there to see them unfortunately.
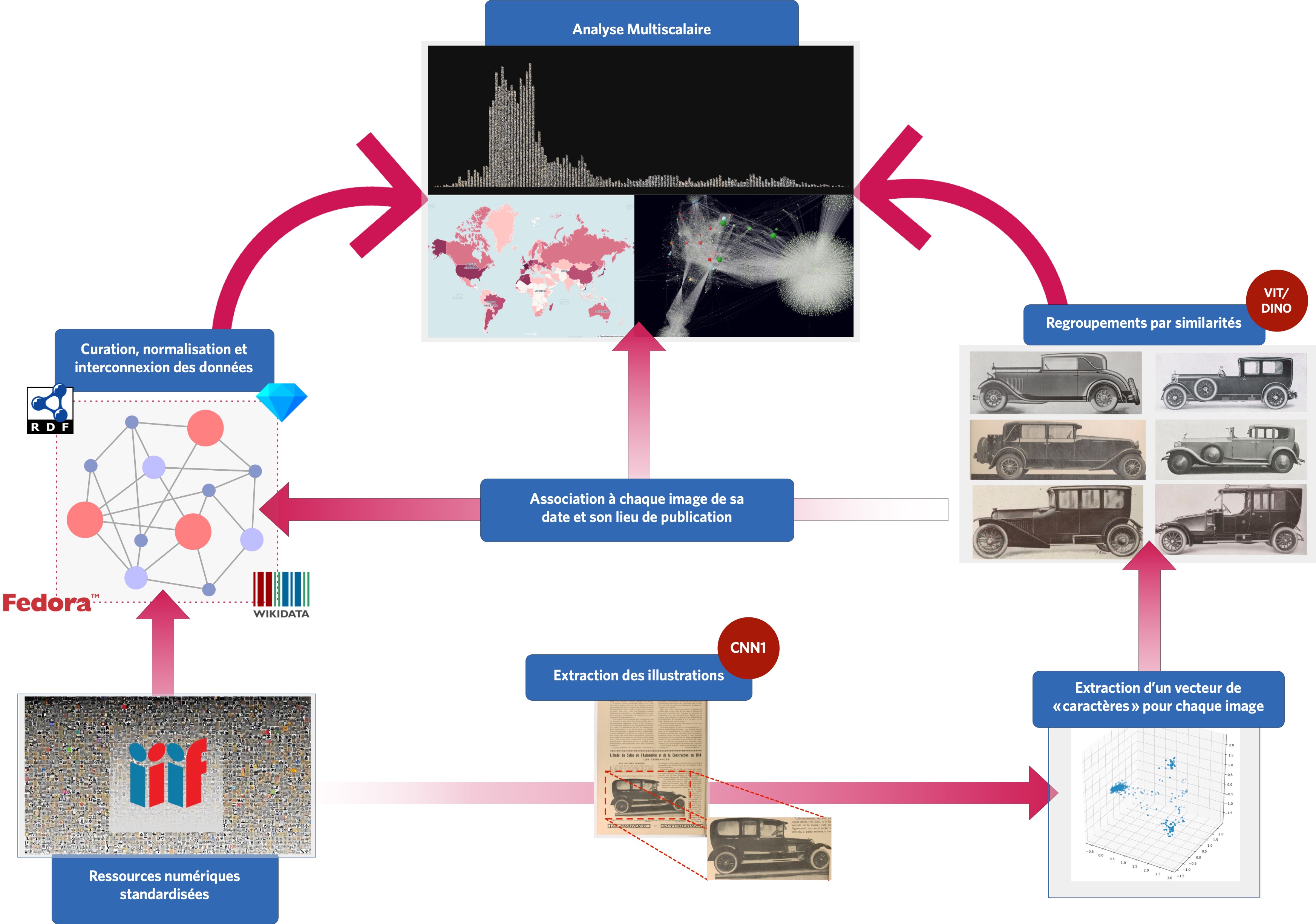
Hence the incentive to describe our images mathematically by vectors, rather than comparing images two by two.
This enables a scalar product from which we construct a similarity score between images. From these vectors, the computer constructs a graph in which it locates the closest subsets of points. Graphically, or rather mathematically, the machine will isolate groups of similar images. We still need to identify the most efficient and fastest algorithms, and to do this we need to compare their results on limited corpora, drawn from our own data. After several evaluations, Visual Contagions adopted the NMSLIB algorithm.
In summary: a computer vision project improves its processing chain through trial and error.
--
Diagram illustrating the extraction, description, analysis and visualisation process used by Visual Contagions.
--
The last element of the chain, the Explore platform, allows to retrieve these groups of similar images, according to a similarity threshold that we define.
Depending on how our algorithms are tuned, they can classify the images into larger or smaller groups depending on how close the images are to each other. The images are then reassociated with their metadata (locations, dates and source of publication). It is then possible to visualise their groupings, to identify the most reproduced images, and to attempt a more general analytical treatment of the global space of illustrations of the first twentieth century.
Go to Episode III : Navigating the Ocean of Images
Go Back:
Our Corpus' Bias
Chapter :
II. Promises of the machine
[1] In this format, each document can be retrieved by a simple Internet address (a URI), which gives access to a very light text file. This file, called a "manifest", contains the list of names of the image files that make up the document, the order and organisation of these pages, and the metadata that describes it: title, date, publisher, archive, date of publication, etc. It is from the internet address of this "manifest" that we find an image as well as its date, place and title of publication.
[2] Jinliang Liu, FanLiang Bu, Improved RANSAC features image-matching method based on SURF, 7th International Symposium on Test Automation and Instrumentation (ISTAI 2018), 2019, https://doi.org/10.1049/joe.2018.9198