Agglomerative clustering based on Euclidean distances among interval scale variables.
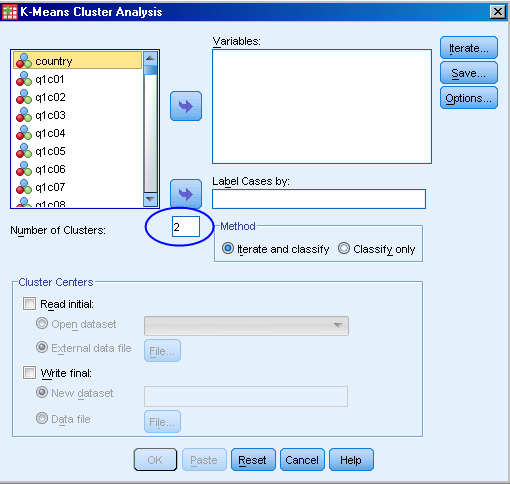
Agglomerative clustering, like K-Means, requires you to specify the number of clusters.
Two different methods are provided : updating cluster centers iteratively (iterate and classify) or classifying only.
 controls the displayed output and lets you change the default missing value handling.
controls the displayed output and lets you change the default missing value handling.
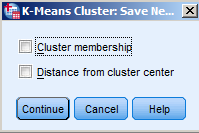 request to copy the cluster membership variable as well as the distance of each
observation from the cluster center.
request to copy the cluster membership variable as well as the distance of each
observation from the cluster center.
Please refer to the SPSS documentation for details (Quick Cluster command).